
An Architectural Deep Dive of Production Grade RAG Systems
Introduction
The journey from a proof-of-concept RAG system to production deployment reveals layers of complexity that fundamentally reshape the initial architecture. What begins as an elegant pipeline of retrieve-then-generate transforms into a sophisticated orchestration of distributed systems, each component requiring careful optimization and monitoring.
Document Ingestion- Where Reality Meets Theory
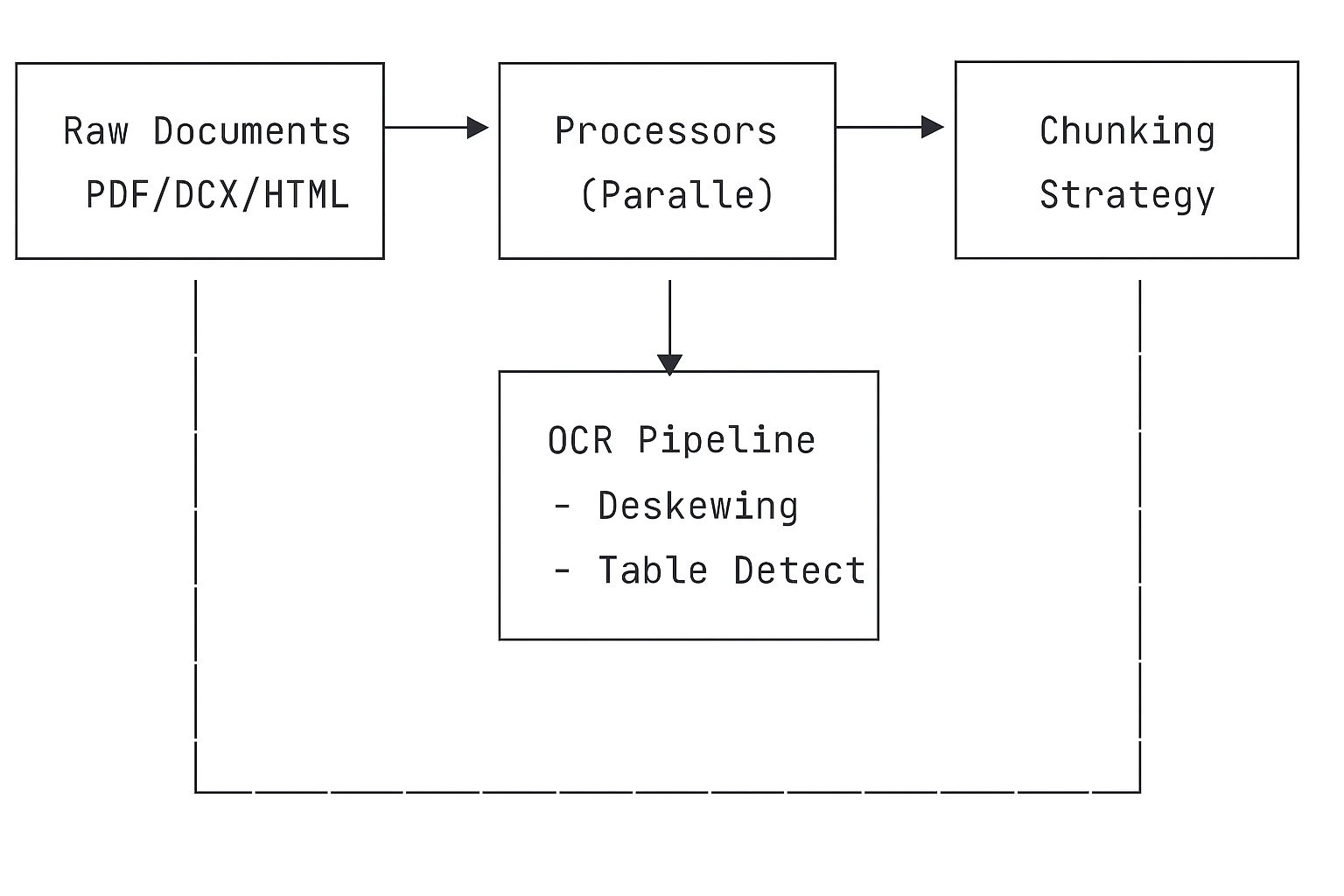
The document processing pipeline represents the first collision between theoretical elegance and practical chaos. Production systems inherit decades of enterprise documents: scanned PDFs at various angles, password-protected files, Excel sheets with data buried in cell comments, and Word documents with tracked changes spanning years.
Document processing becomes a multi-stage pipeline where each document type requires specialized handling. OCR services must handle rotated scans, detect table structures, and preserve layout information. The challenge intensifies when dealing with multi-column layouts, where reading order becomes ambiguous, or technical diagrams where spatial relationships carry semantic meaning.
The Chunking Dilemma
Chunking strategy profoundly impacts retrieval quality. Fixed-size chunking destroys semantic coherence, while semantic chunking must balance completeness with retrieval precision. The challenge multiplies when handling structured documents
Imagine you have a company report with sections, paragraphs, and tables. When preparing this document for RAG, you need to split it into smaller pieces (chunks) that the system can search through. Here's how different chunking approaches handle this:
Original Document Structure Your document has Section 1 with two paragraphs, Section 2 with a paragraph and a financial table, and Section 3 with one paragraph. It's a well-organized hierarchy where each piece has its place and meaning.
Naive Chunking Approach This method blindly cuts every 500 characters, like using scissors on a newspaper without looking. Your financial table showing Q4 results gets chopped in the middle—column headers end up in chunk 1, half the data in chunk 2, and the rest in chunk 3. A sentence like "Our Q4 revenue increased by 25% compared to last year" gets split into "Our Q4 revenue increased by" (chunk 1) and "25% compared to last year" (chunk 2). The system loses all understanding of which paragraph belongs to which section.
Structure-Aware Chunking Solution This approach respects your document's natural boundaries. Section 1 becomes one complete chunk containing both its paragraphs. The financial table stays intact as a single chunk, preserving all rows and columns together. Each chunk carries metadata—like a shipping label—indicating "this is a table from Section 2" or "this is a complete section." When someone searches for "Q4 financial results," the system retrieves the entire table with all its context, not meaningless fragments.
Production systems implement document-aware chunking that preserves tables as atomic units, maintains parent-child relationships, and includes metadata about document structure. This metadata becomes crucial during retrieval when the system needs to understand whether a chunk represents a complete thought or requires additional context.
Hybrid Retrieval Architecture

Pure semantic search fails spectacularly on technical content. The query "Q4 2023 EBITDA" has minimal semantic overlap with the phrase "fourth quarter earnings before interest taxes depreciation and amortization for twenty twenty-three" despite identical meaning. This necessitates a sophisticated hybrid approach
The fusion layer implements Reciprocal Rank Fusion (RRF) to combine results from different retrieval methods. Each retrieval method excels in different scenarios: dense retrieval captures semantic similarity, sparse retrieval handles exact matches and rare terms, while metadata filtering ensures temporal and document-type relevance.
Vector Database Architecture
The choice of vector database profoundly impacts system performance. Initial prototypes using in-memory solutions hit scalability walls around 10 million documents. Production systems require careful consideration of index types

HNSW provides excellent query performance but requires substantial memory. IVF (Inverted File Index) offers better memory efficiency with slightly higher latency. Production systems often implement a tiered approach:
Hot tier: HNSW for frequently accessed, recent documents
Warm tier: IVF with compression for moderate access patterns
Cold tier: Flat indices on object storage for archival content
Accuracy and Hallucination Prevention
Production RAG systems must implement multiple layers of defense against hallucination. Simple cosine similarity thresholds prove insufficient; sophisticated confidence scoring considers multiple factors
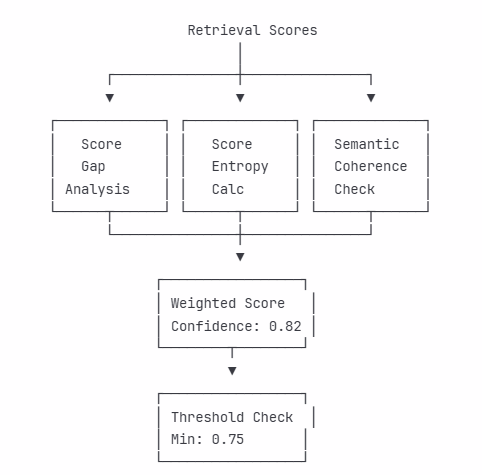
When confidence falls below threshold, the system must gracefully decline to answer rather than generate plausible-sounding fabrications. This requires careful prompt engineering that explicitly instructs the model about uncertainty handling.
Source Attribution Architecture
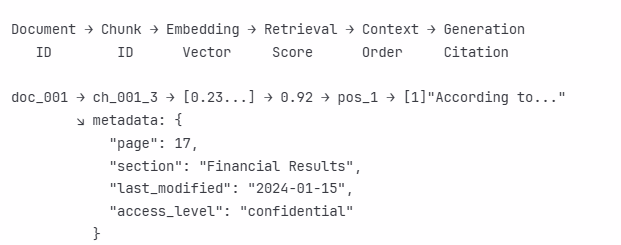
Every claim must be traceable to source documents. This requires maintaining provenance throughout the pipeline
Security and Multi-Tenancy

Multi Tenant Architecture
Enterprise deployments require sophisticated access control that extends beyond document-level permissions. Embeddings themselves can leak information through similarity searches. Consider a scenario where searching for "layoff plans" returns high similarity to documents a user cannot access—even without seeing the documents, the similarity score reveals sensitive information.
This architecture ensures complete isolation between tenants while allowing for resource sharing at the infrastructure level. Each tenant's embeddings remain separate, preventing information leakage through vector similarity.
Performance Optimization
Production systems must balance numerous performance considerations. The complete request flow reveals multiple optimization opportunities

Request Flow Timing Breakdown
Caching strategies must be sophisticated enough to handle semantic similarity rather than just exact matches. A query for "quarterly revenue" should potentially return cached results for "Q4 earnings" if the semantic similarity exceeds threshold and temporal relevance remains valid.
Monitoring and Observability
Production RAG systems require comprehensive monitoring that goes beyond traditional metrics

Observability Stack
Key metrics include not just system performance but semantic quality measures. Normalized Discounted Cumulative Gain (NDCG) and Mean Reciprocal Rank (MRR) provide insights into retrieval quality. User feedback loops enable continuous improvement of ranking algorithms.
Cost Management Architecture
Every component in the RAG pipeline incurs costs that compound at scale

Intelligent caching, index compression, and query routing to appropriately sized models become essential for cost control. Production systems implement sophisticated cost allocation to track usage by team, project, or query type.
Evolution and Maintenance
Production RAG systems are never "complete." They require continuous evolution as document corpuses grow, query patterns shift, and new model capabilities emerge. Successful systems implement gradual rollout strategies.
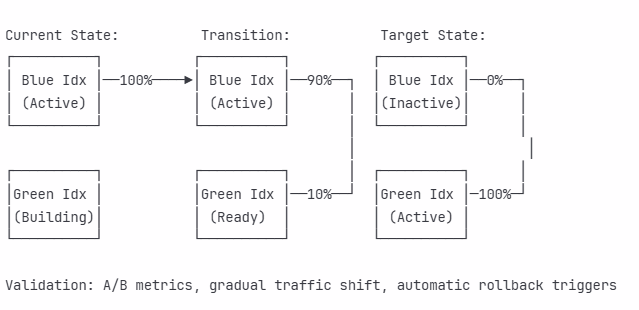
Blue-Green Deployment for Index Updates
This architecture enables zero-downtime updates while maintaining the ability to instantly rollback if quality metrics degrade.
Conclusion
The transformation from proof-of-concept to production RAG represents a journey through increasingly complex architectural decisions. Success requires embracing this complexity while maintaining focus on the core value proposition: providing accurate, fast, and reliable augmented generation at scale. The systems that thrive are those that implement comprehensive monitoring, maintain flexibility for evolution, and never stop optimizing the balance between quality, performance, and cost.
The beauty of production RAG emerges not from any single component but from the orchestration of dozens of subsystems, each finely tuned and working in concert to deliver seamless augmented intelligence to users who neither know nor care about the underlying complexity.